Beta of Neurodata Without Borders Software Now Available

(Originally published by Berkeley Lab Computing Sciences)
December 12, 2017
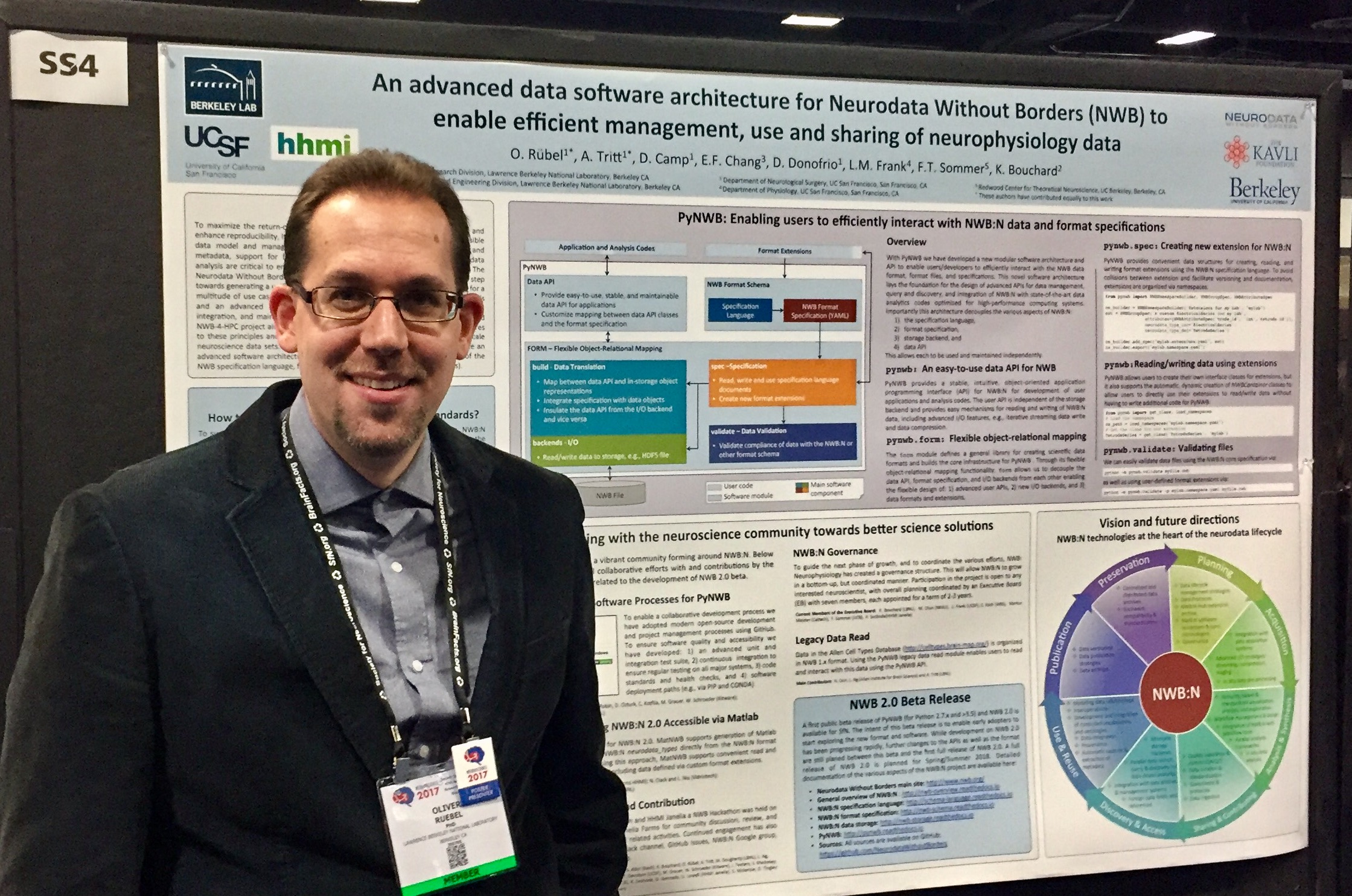
Neuroscientists can now explore a beta version of the new Neurodata Without Borders: Neurophysiology (NWB:N 2.0) software and offer input to developers before it is fully released next year.
The 2.0 software version was developed by Lawrence Berkeley National Laboratory’s (Berkeley Lab’s) Oliver Ruebel and Andrew Tritt, in close collaboration with Kristofer Bouchard (Berkeley Lab), Loren Frank (UCSF; Kavli Institute for Fundamental Neuroscience), Eddie Chang (UCSF), and the broader Neurodata Without Borders (NWB) community. The beta update was announced earlier this year and the team presented a poster of their work at the 2017 Society for Neuroscience meeting in Washington D.C. last month.
NWB is a consortium of researchers and foundations with a shared interest in breaking down obstacles to data use and sharing. The group ultimately aims to standardize neurophysiology data on an international scale to ensure the success of brain research worldwide and accelerate the pace of discovery. It was initiated by The Kavli Foundation in mid-2014 in the wake of the BRAIN Initiative announcement.
“Because the majority of software developed in academic biology labs is done by graduate students and postdocs—who are not trained software engineers—you generally get tools that are not of great quality or durable long term,” says Bouchard, a computational neuroscientist who holds joint appointments in Berkeley Lab’s Computational Research Division (CRD), Biological Systems and Engineering Division, and the Helen Wills Neuroscience Institute at UC Berkeley.
In an effort to maximize the return on investment in the creation of neurophysiology data sets and enhance experiment reproducibility, Bouchard notes that the first version of NWB:N made huge strides toward generating a unified data format for cellular-based neurophysiology data for a multitude of use cases. The 2.0 version of NWB:N builds on its predecessor with an advanced software architecture and application programming interfaces (APIs) that make life easier for the end user.
For instance, the NWB-spec API allows for effective design of format extensions that are customizable to a lab’s needs. PyNWB, a Python library for NWB, then defines a high-level API for interacting with NWB data to facilitate efficient read/ write and integration of the format with user datasets and code bases. An integrated data-build API manages the integration of PyNWB user-interface objects with NWB format specifications to create abstract representations of NWB data containers. The containers are translated to and from NWB:N files on disk via a read/write layer that has been abstracted to enable multiple storage options.
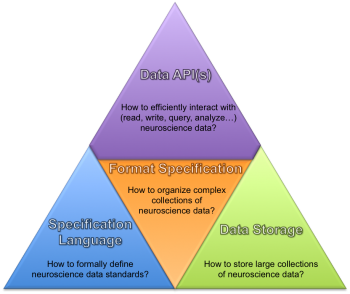
“The idea behind the NWB:N 2.0 software design is to decouple various aspects of the system and create stable, easy-to-use APIs for users and developers that provide critical abstractions from NWB,” says Ruebel, a research scientist in CRD’s Data Analytics and Visualization Group. “Our architecture empowers users to easily access, use and analyze NWB data; integrate NWB with user code bases and develop new extensions for NWB:N.”
“The ability to easily create and access NWB:N format files is critical to enable and enhance broad adoption of the format in neuroscience labs,” adds Bouchard. “The value of science data increases when it can be reused and this is made possible by the investments in a community data model and reference software implementation."
According to Tritt, the new architecture also lays a foundation for the design of advanced APIs for data management, query and discovery, as well as integration of NWB:N with state-of-the-art data analytic codes optimized for high performance computing systems.
“Berkeley Lab—Oliver Ruebel and Andrew Tritt in particular—have a long history of developing sustainable, well-engineered scientific software for biologists. They have the expertise and collaborative spirit to work with a diversity of researchers,” says Bouchard. “Berkeley Lab’s extensive tradition of creating computational tools and techniques for science is one big reason why NWB:N 2.0 is poised to become a community standard.”
According to Bouchard, Berkeley Lab’s leadership in the NWB:N development would not be possible without the Laboratory Directed Research and Development (LDRD) project BRAINformat: A Data Standardization Framework for Neuroscience Data. By proving their concept at a hackathon in 2014, the Berkeley Lab team caught the attention of the neuroscience community and was then invited to join discussions about NWB and novel concepts for standardization.
“In my own lab, until recently, standardization and the sharing of data was done in an ad hoc fashion,” says Bouchard. “Having this standard has accelerated the sharing of data even within my own lab.”
In addition to finalizing NWB:N 2.0 , Bouchard, Ruebel and Tritt are also working on algorithms that will ingest the NWB data formats to run at scale on high performance computing systems at the Department of Energy’s National Energy Research Scientific Computing Center (NERSC).
The Kavli Foundation supported this work via the NWB-4-HPC project. NERSC is a DOE Office of Science User Facility located at the Berkely Lab.
Download NWB:N 2.0: https://www.nwb.org/2017/11/11/nwb-2-0-beta-released/